|
(2.1) |
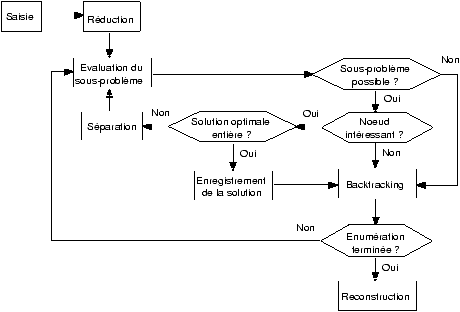
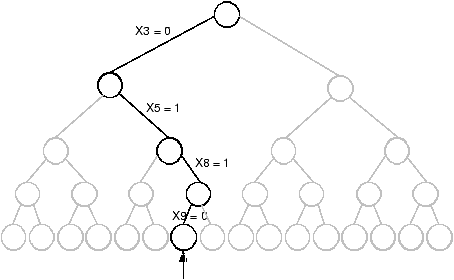
Pour être complet, cette notation comprend aussi un pointeur permettant de connaître les noeuds déjà explorés. Cependant celui-ci n'est pas utile dans notre cas car comme nous le verrons, les règles de séparation et de backtracking employées évitent de revenir sur un noeud déjà rencontré.